
Sharding
In this article we shall discuss the concepts of sharing (multi-processing) using the base cases extracted from Proof-Of-Work blockchains and then conclude with how CSPR is researching and developing their methodology for sharding.
Typical POW blockchains have an issue with scalability. As the blockchain grows, so does the amount of data stored on each computer in peer to peer network. The reason for this is the authentication process. Transactions are authenticated via consensus protocols. As the name suggests, a majority of approving nodes needs to agree upon a transaction before the block can be appended to the blockchain. POW blockchains require each authenticating node to record all the data on the blockchain and process all the transactional load. But as more transactions occur and the blockchain grows, because each node has to process everything (massive duplication of work) the entire network slows. Below are approximate max transactions per second for BTC and ETH. To put this into context, VISA (the payment network) can process 1,700 transactions per second.
- BTC: 7 transactions per sec
- ETH: 30 transactions per sec
Blockchains have to be able to grow exponentially without slowing. That means making it ‘scalable’. The below image illustrates how scalability is one of the three competing factors in optimal blockchain. Solving all 3 will result in a truly future proof blockchain. We shall discuss also how solving 1 of the 3 principals below, is often to the detriment of another principal.

Sharding – Databases
As mentioned above, due to the fact that each node must process every transaction there will be an inherent limitation to the network. This comes about as the computing and load power on each node grow directly proportional to the growth of transactions on the network. Consider the below analogy:
Consider a fast food take away counter. If there is 1 staff member on the till and the queue of customers grow, the workload of that till person will grow proportionally to the length of the queue. The reason being that they have to process the orders of everyone in the queue.
Now imagine increasing the number of till staff to 2 people. If each till person has to process every order, then you have not implemented any time saving – you have merely duplicated work.
Time saving is only implemented if you split the queue of customers equally among the two tills. This way you will have doubled the throughput.
ghost analogy
In order then to increase throughput, we must split the workload among the nodes such that we can process transactions in parallel.
Sharding is a concept and technique used in databases for horizonal partitioning. It is where you separate the rows from one larger table into multiple smaller tables. Each new table (or partition) has the same schema and columns, but also entirely different rows. Likewise, the data held in each is unique and independent of the data held in other partitions. Database shards exemplify a shared-nothing architecture. This means that the shards are autonomous; they don’t share any of the same data or computing resource. The main appeal of sharding a database is that it can help to facilitate horizontal scaling, also known as scaling out. Horizontal scaling is the practice of adding more machines to an existing stack in order to spread out the load and allow for more traffic and faster processing. This is often contrasted with vertical scaling, otherwise known as scaling up, which involves upgrading the hardware of an existing server, usually by adding more RAM or CPU.
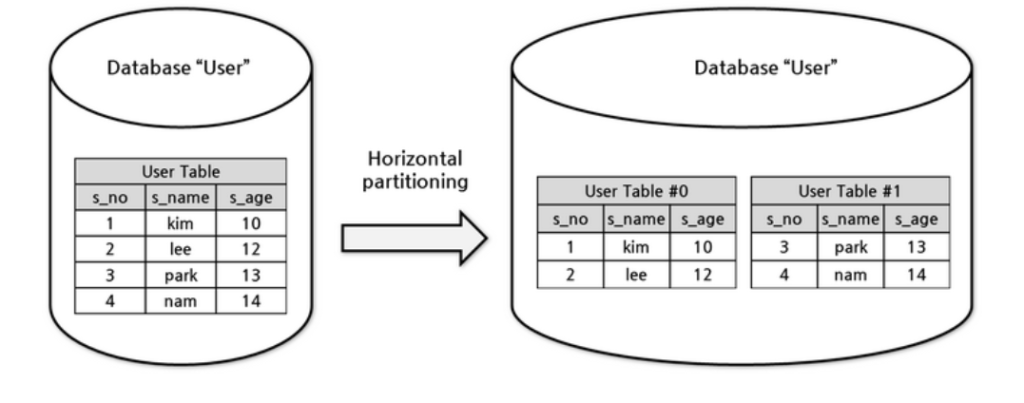
Sharding – Blockchains
We can take the above and apply the same concepts to blockchain nodes. By splitting the population of nodes into shards (smaller groups of nodes within the population), we can then split the transactional workload among these shared to achieve parallel processing of transactions, thus increasing throughput. Each of the nodes within a given shard will only need to store and process the transactions allocated to that shard. The information in a shard can still be shared and everyone can still see all the ledger entries, however every node is freed from storing and recording data on other nodes. That allows data to be stored more quickly and is easier to find as its location is mapped on the blockchains.
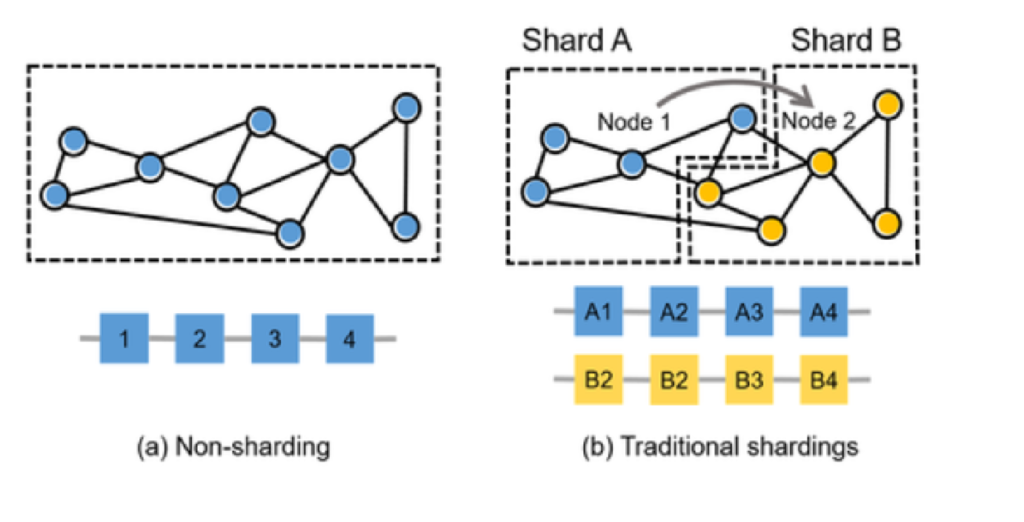
You may be thinking now that in implementing sharding (scalability in our blockchain trilemma), we have actually reduced the security of the network…and you would be correct. The reason for this is that to maintain security, you need to guard against something called ‘Shard Takeover’
Shard Takeover
One upside to have every node record all transactions is that data is undisputable as there are as many copies and potential consensus agreements as there are number of nodes.
If for example we now create as many shards as there are number of nodes where each shard only records transactional data that it is processing, we have increased the throughput by a factor of the number of nodes, but have introduced massive risks. The reason for the risks is that there is now no copy of the data on any given node and so any corruption of nodes will result in permanent loss of data.
Additionally to the above risks in corruption, there is also risks of malicious behaviour by nodes. Any malicious behaviour in the example above will also result in permanent loss of data.
Shard Optimization
In the article so far we have discussed two limiting cases:
- Fully decentralized with no sharding – performance and scaling issues
- Applying maximum sharding such that the number of shards equals the number of nodes – security issues
We therefore have an optimization problem to solve. ie finding the sweet spot between security and performance. In later articles I will go over some mechanisms to solve this optimization problem and also techniques to further improve sharding.
CSPR Sharding
The below extract was taken from our AMA with the CasperLabs CTO Medha Palikar:
Daniel Kane has started the work on sharding – here are his initial ideas:
- The memory space of our virtual machine is divided up into shards. Shards might reasonably be quite small. For example, by default we could make a shard the memory associated with a single account or smart contract. On the other hand, we might want them to be a bit bigger, to, for example, be large enough that they approximately take up an entire disk.
- Transactions must include a list of all of the shards whose memory they might need to access. A transaction that fails to list all shards it tries to access will fail.
- Each block is given a limited amount of sequential compute time (perhaps a constant or perhaps proportional to the number of tics that have passed since the parent block), and perhaps also given a bounded amount of total compute.
- When a block includes a bunch of transactions instead of specifying a transaction order, it specifies a computation schedule. This schedule uses times from 0 to t where t is our bound on sequential compute time. Each transaction is assigned a sub-interval of this window with the length of the sub-interval given by the computation bound specified by the transaction. Furthermore, the intervals for any two transactions that share a shard are not allowed to overlap. We might make a distinction between reads to a shard and writes to a shard and allow several transactions to simultaneously read from the same shard so long as none write to it. We might also require that the total length of the intervals not exceed some total computation bound or the number of windows overlapping at the same time not exceed some bound.
This should ensure that the transactions within a block are reasonably parallelizable, as the computation schedule essentially provides a mechanism for parallelizing the computation. Furthermore, this mechanism should produce the same results as if the computations were atomic with each operation being performed at some arbitrary time during its interval.
Because each block supports parallel execution, should not affect security.
Disclaimer: This article is written for the purposes of research and does not constitute financial advice or a recommendation to buy.